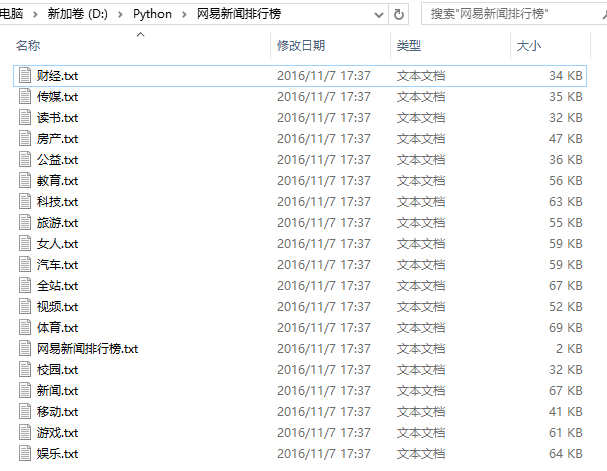
今天给大家更新个文章~利用Python写一个自动爬网易新闻排行榜的脚本.
版本:Python 3.5
import os
import urllib
import requests
import re
from lxml import etree
def savepath(path,fileName,message):
#判断path文件夹是否存在,如果不存在则创建
if not os.path.exists(path):
os.mkdir(path)
#拼接的是完整的文件名字fileName = '体育'
#newFileName = '体育'.txt
newFileName = fileName + '.txt'
#拼接储存文件的路径(获取的是存储数据文件的绝对路径)
newFile = os.path.join(path,newFileName)
#将列表message 写入本地
with open(newFile, 'w+',encoding = 'utf-8') as f:
for s in message:
f.write('%s %s'%(s[0],s[1]))
#这个函数的作用是解析漏洞新闻排行榜的子标题
def messageinfo(page):
#re模块是Python中的正则表达式的模块
#re.findall 表示通过正则获取数据
#会获取匹配到的所有字符
messageinfo = re.findall('<div class="titleBar" id=".?"><h2>(.?)</h2><div class="more"><a href="(.?)">.?</a></div></div>',page,re.S)
return messageinfo
def page_info(page):
dom = etree.HTML(page)
#dom.xpath()在html中查找标签的函数
#找tr标签中的td,td中的a标签,a标签中的text内容
title = dom.xpath('//tr/td/a/text()')
#找tr标签中的td,td中的a标签,a标签中的href的内容
url = dom.xpath('//tr/td/a/@href')
new_list = []
for X in range(len(title)):
new_tuple = (title[X],url[X])
new_list.append(new_tuple)
return new_list
def Spider(url):
#request.get 做URL请求
#content 获取请求的内容
#decode 做gbk的编码
message = requests.get(url).content.decode('gbk')
message_List = message_info(message)
message_path = u'网易新闻排行榜'
message_fileName = u'网易新闻排行榜'
save_path(message_path,message_fileName,message_List)
for item,url in message_List:
print(item,url)
new_message = requests.get(url).content.decode('gbk')
new_message_list = page_info(new_message)
print(new_message_list)
save_path(message_path,item,new_message_list)
if __name == '__main':
start_URL = 'http://news.163.com/rank/'
Spider(start_URL)效果演示: